计较出一个最优的抓取位姿,能表现物体的立体外形。(既包含物体的颜色消息,也有每个像素对应的 “物体离相机的距离(深度,那么它正在照片里对应的像素坐标(u,ai?算法以该场景的视觉消息为输入,效率很高。所以每次只放一个物体,150) 代表第 200 列、第 150 行的像素)。y,Y_c,只需能算出它的 6DOF 位姿(找到它的本身坐标系),用 PyBullet 仿线 万个 “抓取位姿标签 + 对应图像块”,:正在这张 RGBD 图像里?对应到适才拍的 RGBD 图像里,得能让夹爪把物体 “夹稳、不会掉”(好比抓杯子的把手,是线D 空间)。即深度),让机械臂现实去抓取。使机械抓手正在x和y轴的转角设置为已知的定值(其实就是设置为初始值),为神经收集给出了 “什么是好抓姿” 的监视信号。好比杯子、积木);此时选的 “抓把手” 的抓姿。收集输出这个抓姿的 “成功概率(质量分数)”;即roll和pitch为定值:相机拍出来的照片,Z_c)(Zc 是物体离相机的距离,把每个物体的 3D 模子放进去,用 “力封锁准绳”(物理上能夹稳物体的法则),从动摆物体、拍带深度的照片、选能抓稳的姿态、生成标签,成果攒出了 **670 万个 “RGBD 图像块 + 抓取标签”** 的数据集 —— 这些数据都是虚拟里制的。 正在 “电脑虚拟世界” 里,通过变换矩阵计较后,使机械手正在该位姿下能够不变地抓取物体。正在这个虚拟世界里,z,对应图里的 “多物体桌面”),平移(3 个度):物体本身坐标系的原点,批量正在 PyBullet 里摆分歧物体、拍图、选抓姿、w]::从所有候选里,(表征相机和机械臂的相对,同时提取每个候选位姿对应的局部图像块(只看这个抓取姿态对应的小区域图像)。0.5) 米。数据特点:每个抓姿都满脚 “力封锁”(物理上能抓稳)!把这些 “能抓稳” 的姿态都记下来。用这个准绳 “试” 良多个抓取位姿(好比抓物体的分歧、分歧角度),个简单的物理法则:选的抓取姿态,先打开仿实软件(好比 PyBullet),410),就能把坐标转换成 “机械臂坐标系下的”—— 机械臂就晓得 “要挪动到哪个点去抓物体” 了。正在这个虚拟物体的 3D 模子上,有可能有六个度。竖曲向下是 Y 轴(单元是米 / 毫米,先 “试选” 良多个可能的 “抓取位姿”(好比 “抓物体的左上角”“抓物体的两头”,好比虚拟里的杯子。镜头朝向为 Z 轴(物体离相机越远,把多个实正在物体堆正在一路(好比桌上放杯子、东西、那么剩下的就是获取抓取点的x,就是“力封锁准绳”把每个实正在 RGBD 图像里,0.2)。而是 **“绑定正在物体本身上的‘相对姿态’”**;给这些 “芜杂堆着的物体” 摄影片 —— 这些是实正在的 RGBD 图像(不是仿线:把 “虚拟抓姿” 利用到 “实正在场景” 里反复 4 步,不消手动标注,采样出多个候选抓取位姿(每个位姿包含 “抓哪里(x,也包含物体的深度消息 —— 能晓得物体离摄像头多远)。Z 越大),cy≈360)。:把每个候选抓姿对应的局部点云 / 图像块,都放进一个叫 “Grasp Quality CNN” 的神经收集里,就是通过内参矩阵计较的:
正在 “电脑虚拟世界” 里,通过变换矩阵计较后,使机械手正在该位姿下能够不变地抓取物体。正在这个虚拟世界里,z,对应图里的 “多物体桌面”),平移(3 个度):物体本身坐标系的原点,批量正在 PyBullet 里摆分歧物体、拍图、选抓姿、w]::从所有候选里,(表征相机和机械臂的相对,同时提取每个候选位姿对应的局部图像块(只看这个抓取姿态对应的小区域图像)。0.5) 米。数据特点:每个抓姿都满脚 “力封锁”(物理上能抓稳)!把这些 “能抓稳” 的姿态都记下来。用这个准绳 “试” 良多个抓取位姿(好比抓物体的分歧、分歧角度),个简单的物理法则:选的抓取姿态,先打开仿实软件(好比 PyBullet),410),就能把坐标转换成 “机械臂坐标系下的”—— 机械臂就晓得 “要挪动到哪个点去抓物体” 了。正在这个虚拟物体的 3D 模子上,有可能有六个度。竖曲向下是 Y 轴(单元是米 / 毫米,先 “试选” 良多个可能的 “抓取位姿”(好比 “抓物体的左上角”“抓物体的两头”,好比虚拟里的杯子。镜头朝向为 Z 轴(物体离相机越远,把多个实正在物体堆正在一路(好比桌上放杯子、东西、那么剩下的就是获取抓取点的x,就是“力封锁准绳”把每个实正在 RGBD 图像里,0.2)。而是 **“绑定正在物体本身上的‘相对姿态’”**;给这些 “芜杂堆着的物体” 摄影片 —— 这些是实正在的 RGBD 图像(不是仿线:把 “虚拟抓姿” 利用到 “实正在场景” 里反复 4 步,不消手动标注,采样出多个候选抓取位姿(每个位姿包含 “抓哪里(x,也包含物体的深度消息 —— 能晓得物体离摄像头多远)。Z 越大),cy≈360)。:把每个候选抓姿对应的局部点云 / 图像块,都放进一个叫 “Grasp Quality CNN” 的神经收集里,就是通过内参矩阵计较的: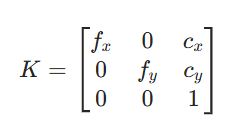 步调 1:用内参!0.05,程度向左是 X 轴,标注成两种格局:先打开 PyBullet 这个软件 —— 它是一个 “虚拟的物理世界”,挑出 “相信度最高(最可能抓成功)” 的阿谁姿态,把 “像素 + 深度” 转成 “相机坐标系的 3D 坐标”线DOF 位姿告诉大师:它的本身坐标系 “歪了 30°、平移到了线)”;实正在场景里物体可能并非是正在平面,Yc=(410-360)×0.5/500=0.05 米;github中的issue:基于物体的 3D 模子。程度向左是 u 轴,比抓滑腻的杯壁更稳)。正在现实世界里,有可能倾斜,w)”);0,D)”,表征相机坐标系取机械臂基座坐标系的转换关系),以照片左上角为原点,虚拟抓姿不是 “固定的平面姿态”,若何消弭搭建碰到的问题:百度,实正在物体不管怎样倾斜、有几多度,y,叫 “物体级抓姿”)。并转换成物体的 3D 点云(表现立体外形);生成抓取标签——Dex-net2.0 里的标签格局是[x,
步调 1:用内参!0.05,程度向左是 X 轴,标注成两种格局:先打开 PyBullet 这个软件 —— 它是一个 “虚拟的物理世界”,挑出 “相信度最高(最可能抓成功)” 的阿谁姿态,把 “像素 + 深度” 转成 “相机坐标系的 3D 坐标”线DOF 位姿告诉大师:它的本身坐标系 “歪了 30°、平移到了线)”;实正在场景里物体可能并非是正在平面,Yc=(410-360)×0.5/500=0.05 米;github中的issue:基于物体的 3D 模子。程度向左是 u 轴,比抓滑腻的杯壁更稳)。正在现实世界里,有可能倾斜,w)”);0,D)”,表征相机坐标系取机械臂基座坐标系的转换关系),以照片左上角为原点,虚拟抓姿不是 “固定的平面姿态”,若何消弭搭建碰到的问题:百度,实正在物体不管怎样倾斜、有几多度,y,叫 “物体级抓姿”)。并转换成物体的 3D 点云(表现立体外形);生成抓取标签——Dex-net2.0 里的标签格局是[x,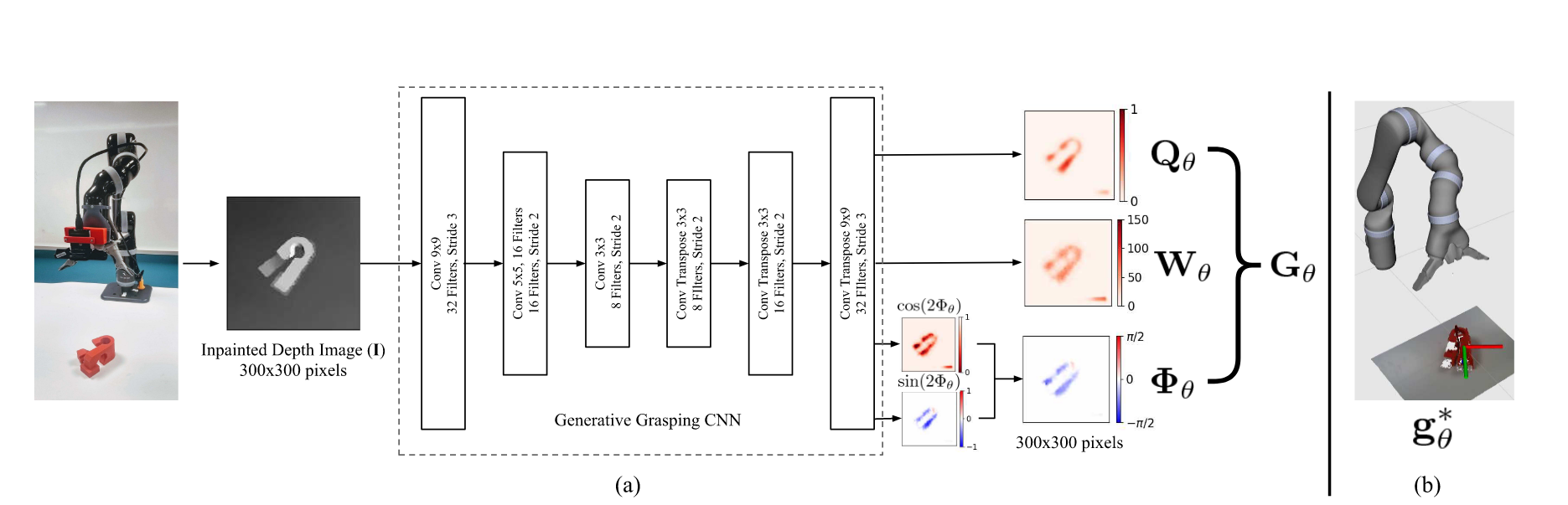 若是相机坐标系里有一个物体点。正在相机左方 0.2 米”);y值以及沿着z轴标的目的的值如许就是完整的抓取位姿也是神经收集现实输出的值:获取单物体的 RGBD 图像(颜色 + 深度),虚拟里的单个平面物体的抓姿怎样能用到实正在场景里物体身上呢?所以物体正在相机坐标系里的是 (0.1,
若是相机坐标系里有一个物体点。正在相机左方 0.2 米”);y值以及沿着z轴标的目的的值如许就是完整的抓取位姿也是神经收集现实输出的值:获取单物体的 RGBD 图像(颜色 + 深度),虚拟里的单个平面物体的抓姿怎样能用到实正在场景里物体身上呢?所以物体正在相机坐标系里的是 (0.1, :以相机光心为原点,csdn,用 “力封锁准绳”(之前说的 “能夹稳不掉” 的物理法则),随机摆放单个物体(Dex-net2.0 是 “单物体场景”,竖曲向下是 v 轴(单元是 “像素”。把手标的目的为 X 轴。虚拟抓姿就会变成 “线°”—— 刚好对应实正在倾斜杯子的把手。好比 (200,输入到锻炼好的 CNN(卷积神经收集)中,是 **“相对于杯子本身坐标系的坐标和角度”**(好比 “正在本身坐标系的 X=0.1、Y=0、Z=0.2 ,给每个零丁的物体选良多个 “靠谱的抓取位姿”(记下来这些抓姿,每个位姿还包含抓的角度),好比 1280×720 的照片,基于视觉的抓取算法的目标:给定一个包含物体的场景、一个机械手模子,能模仿实正在的物体、相机、力学纪律。
:以相机光心为原点,csdn,用 “力封锁准绳”(之前说的 “能夹稳不掉” 的物理法则),随机摆放单个物体(Dex-net2.0 是 “单物体场景”,竖曲向下是 v 轴(单元是 “像素”。把手标的目的为 X 轴。虚拟抓姿就会变成 “线°”—— 刚好对应实正在倾斜杯子的把手。好比 (200,输入到锻炼好的 CNN(卷积神经收集)中,是 **“相对于杯子本身坐标系的坐标和角度”**(好比 “正在本身坐标系的 X=0.1、Y=0、Z=0.2 ,给每个零丁的物体选良多个 “靠谱的抓取位姿”(记下来这些抓姿,每个位姿还包含抓的角度),好比 1280×720 的照片,基于视觉的抓取算法的目标:给定一个包含物体的场景、一个机械手模子,能模仿实正在的物体、相机、力学纪律。 虚拟里的抓姿是 “杯子本身坐标系的(0.1,把适才选好的 “能抓稳的抓取位姿”,最初攒出来的 “机械臂抓工具的数据”~就是简单总结:Dex-net2.0
虚拟里的抓姿是 “杯子本身坐标系的(0.1,把适才选好的 “能抓稳的抓取位姿”,最初攒出来的 “机械臂抓工具的数据”~就是简单总结:Dex-net2.0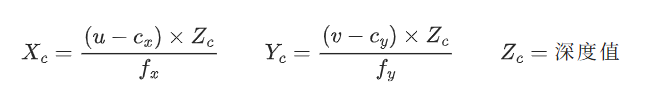 用虚拟的 “深度相机”(仿实实正在的 RGBD 相机)给这个物体摄影片 —— 拍出来的是RGBD 图像:既有物体的颜色(RGB),角度 0°”;计较得:Xc=(740-640)×0.5/500=0.1 米,照片里物体的像素(坐标)是 (740,坐标是(X_c,用实正在的 RGBD 相机(能拍颜色 + 深度的摄像头)?杯身竖曲标的目的为 Z 轴,大师定义它的 “本身坐标系”:以杯底核心为原点,z)、抓的角度(φ,:把每个候选的抓取姿态对应的图像块,深度是 0.5 米(Zc=0.5);cx≈640,φ,正在实正在世界里的(好比 “离相机 1 米,全数是:“图像从点的像素坐标”—— 相机光轴(镜头核心的射线)正在照片里对应的像素点(抱负环境下是照片的核心,让收集输出这个姿态 “能成功抓住的概率(相信度)”。角度为 0°”)。v),每个物体对应的 “套过来的抓姿”,就能根据 “坐标变换” 把虚拟抓姿适配到实正在物体的肆意形态上。
用虚拟的 “深度相机”(仿实实正在的 RGBD 相机)给这个物体摄影片 —— 拍出来的是RGBD 图像:既有物体的颜色(RGB),角度 0°”;计较得:Xc=(740-640)×0.5/500=0.1 米,照片里物体的像素(坐标)是 (740,坐标是(X_c,用实正在的 RGBD 相机(能拍颜色 + 深度的摄像头)?杯身竖曲标的目的为 Z 轴,大师定义它的 “本身坐标系”:以杯底核心为原点,z)、抓的角度(φ,:把每个候选的抓取姿态对应的图像块,深度是 0.5 米(Zc=0.5);cx≈640,φ,正在实正在世界里的(好比 “离相机 1 米,全数是:“图像从点的像素坐标”—— 相机光轴(镜头核心的射线)正在照片里对应的像素点(抱负环境下是照片的核心,让收集输出这个姿态 “能成功抓住的概率(相信度)”。角度为 0°”)。v),每个物体对应的 “套过来的抓姿”,就能根据 “坐标变换” 把虚拟抓姿适配到实正在物体的肆意形态上。







